
오늘도 Do it! 쉽게 배우는 R 데이터분석을 참고했습니다
결측치는 NA
먼저 결측치가 포함된 데이터 프레임 생성
df <- data.frame(sex=c("M","F",NA,"M","F"),
score = c(5,4,3,4,NA))
dfR에서는 결측치를 대문자 NA로 표기합니다
NA 앞뒤에는 따옴표가 없습니다. 따옴표가 있다면 결측치가 아닌 영문자 "NA" 를 의미한다
결측치 확인하기 - is.na()
is.na(df) #결측치 확인
## sex score
##[1,] FALSE FALSE
##[2,] FALSE FALSE
##[3,] TRUE FALSE
##[4,] FALSE FALSE
##[5,] FALSE TRUE결측치는 TRUE, 결측치가 아닌 값은 FALSE로 표시한다
sex의 3행, score의 5행이 결측치이다
table(is.na(df)) #결측치 빈도 출력
##FALSE TRUE
## 8 2
table(is.na(df$sex)) #sex 결측치 빈도 출력
##FALSE TRUE
## 4 1
table(is.na(df$score)) #score 결측치 빈도 출력
##FALSE TRUE
## 4 1table함수와 같이 쓰면 결측치가 몇 개 인지 알 수 있다
전체 데이터 중 결측치 개수를 알수도 있지만 변수를 지정해서 결측치 개수를 알 수도 있다
mean(df$score)
##[1] NA
sum(df$score)
##[1] NA결측치가 포함되어 있으면 연산이 되지 않는다
결측치 제거
!is.na()
library(tidyverse)
dfnomiss <- df %>% filter(!is.na(score)) #score 열에서 결측치가 없는 행만 추출
mean(dfnomiss$score)
##[1] 4결측치를 제외하고는 연산이 가능하다.
sex 열에서도 결측치를 같이 제고 하고 싶다면 아래 코드를 쓰면 된다
df_nomiss <- df %>% filter(!is.na(score) & !is.na(sex))
df_nomiss
##sex score
##1 M 5
##2 F 4
##3 M 4&연산자로 엮어주기
na.omit()
결측치가 하나라도 있다면 한번에 제거 해줌
df_2 <- na.omit(df)
df_2
##sex score
##1 M 5
##2 F 4
##4 M 4간편하긴 하지만, 분석에 필요한 행까지 손실된다는 단점이 있다.
함수에서 결측치 제외 기능 이용하기 : na.rm = TRUE
mean(df$score, na.rm=T)
##[1] 4
summarise를 통해 평균을 구할 때도 사용 가능하다
평균 뿐만 아니라 합계, 중앙값 등 다른 수치 연산 함수들도 na.rm을 지원한다
결측치 대체하기
exam <- read.csv("csv_exam.csv") # 데이터 불러오기
exam[c(3, 8, 15), "math"] <- NA # 3, 8, 15행의 math에 NA 할당
mean(exam$math, na.rm = T) # 결측치 제외하고 math 평균 산출
## [1] 55.23529
exam$math <- ifelse(is.na(exam$math), 55, exam$math) # math가 NA면 55로 대체
table(is.na(exam$math)) # 결측치 빈도표 생성
##
## FALSE
## 203,8,15행에 NA를 할당했다
mean을 구할 땐 na.rm = T를 사용하여 결측치를 제외하고 평균을 산출했다
이후 대체하기 위해서 ifelse 함수를 사용했다
table과 !is.na()함수를 통해 결측치가 대체된 것을 확인
exam # 출력
## id class math english science
## 1 1 1 50 98 50
## 2 2 1 60 97 60
## 3 3 1 55 86 78
## 4 4 1 30 98 58
## 5 5 2 25 80 65
## 6 6 2 50 89 98
## 7 7 2 80 90 45
## 8 8 2 55 78 25
## 9 9 3 20 98 15
## 10 10 3 50 98 45
## 11 11 3 65 65 65
## 12 12 3 45 85 32
## 13 13 4 46 98 65
## 14 14 4 48 87 12
## 15 15 4 55 56 78
## 16 16 4 58 98 65
## 17 17 5 65 68 98
## 18 18 5 80 78 90
## 19 19 5 89 68 87
## 20 20 5 78 83 58
mean(exam$math) # math 평균 산출
## [1] 55.23,8,15행 math 열에 55가 할당되어있음을 볼 수 있다
이상치 제거하기
이상치는 정상 범주에서 크게 벗어난 값을 말한다.
굉장히 드물게 발생하는 극단적인 값은 분석결과를 왜곡시킬 수 있기 때문에 제거해야한다
outlier <- data.frame(sex = c(1, 2, 1, 3, 2, 1),
score = c(5, 4, 3, 4, 2, 6))
outlier
## sex score
## 1 1 5
## 2 2 4
## 3 1 3
## 4 3 4
## 5 2 2
## 6 1 6sex = 1,2 둘중 하나로 분류됨
score = 1~5 값만 가질 수 있음
sex = 3, score = 6인 이상치가 포함된 데이터 생성
이상치 확인하기
table(outlier$sex)
##
## 1 2 3
## 3 2 1
table(outlier$score)
##
## 2 3 4 5 6
## 1 1 2 1 1table 함수를 통해 빈도수를 확인해보면 이상치를 쉽게 확인할 수 있다
sex = 3, score =6인 값이 1개씩 있으므로 하나씩 처리해줘야한다
# sex가 3이면 NA 할당
outlier$sex <- ifelse(outlier$sex == 3, NA, outlier$sex)
# score가 1~5 아니면 NA 할당
outlier$score <- ifelse(outlier$score > 5, NA, outlier$score)
outlier
## sex score
## 1 1 5
## 2 2 4
## 3 1 3
## 4 NA 4
## 5 2 2
## 6 1 NAifelse를 사용해서 NA 결측치로 만들어주고 이 다음은 위에 na.rm를 사용해서 연산을 진행하면 된다
극단적인 값! - box plot
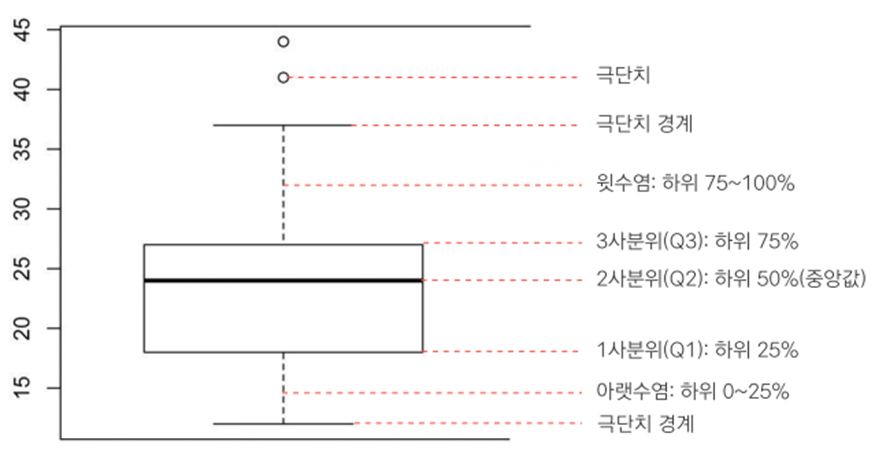
box plot : 상자 그림을 통해 극단치를 확인할 수 있다
mpg <- as.data.frame(ggplot2::mpg)
boxplot(mpg$hwy)$stats # 상자그림 통계치 출력
## [,1]
## [1,] 12
## [2,] 18
## [3,] 24
## [4,] 27
## [5,] 37
## attr(,"class")
## 1
## "integer"mpg 데이터를 사용하여 box plot 통계치를 출려했다
아래쪽 이상치 경계 12
1사분위수 18
중앙값 24
3사분위수 27
위쪽 이상치 경계 37
12~37을 벗어나면 이상치로 분류됨
이상치 처리는 ifelse를 사용해 처리할 수 있다
# 12~37 벗어나면 NA 할당
mpg$hwy <- ifelse(mpg$hwy < 12 | mpg$hwy > 37, NA, mpg$hwy)
table(is.na(mpg$hwy))
##
## FALSE TRUE
## 231 3오늘 외울 것
NA 결측치
결측치가 포함되어 있으면 연산이 되지 않음
na.rm = T를 통해 결측치를 제외하고 연산해야함
outlier 이상치
box plot를 통해 쉽게 확인할 수 있음
'R' 카테고리의 다른 글
| R - 그래프 살펴보기(ggplot2 - 선그래프, 상자그림) (1) | 2024.07.27 |
|---|---|
| R - 그래프 살펴보기(ggplot2 - 산점도, 막대그래프) (2) | 2024.07.13 |
| R - 데이터 추출하기(dplyr : 문제 복습) (0) | 2024.07.11 |
| R 내장 함수 - 데이터 추출 (indexing) (0) | 2024.07.10 |
| R dplyr 패키지 이용하기 - %>% 파이프라인 연산자 (1) | 2024.07.08 |



